Principal Architect - AI Compiler
Microsoft
Biography
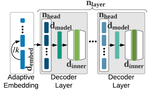
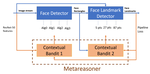
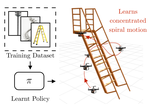
My mission is to make Generative AI more efficient: from more efficient foundational models, to more efficient agentic workflows. My efforts can largely be grouped under the theme of AI for AI Systems. I draw from my core background in Reinforcement Learning, Imitation Learning, Planning and Combinatorial Optimization to aid me in this mission. I am an architect at Microsoft working on using evolutionary search and reinforcement learning to optimize kernels for Nvidia, AMD and MAIA (Microsoft AI Accelerator) hardware.
My superpower is leading lean, agile teams of AI researchers and engineers from fundamental research to product:
-
I built a team of 7 researchers and engineers dedicated to Neural Architecture Search at Microsoft Research, Redmond (2020-2023). My team published multiple NeurIPS, ICLR, ICML high-impact papers. Models from this research serve as efficient, real-time, on-device, text-prediction models for Microsoft Outlook, Word, PowerPoint and Teams which serve billions of queries a month.
-
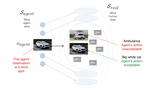
I co-invented AirSIM which has become the leading open-source Robotics simulator and also spawned an enterprise-grade product at Microsoft. (2016-2017)
-
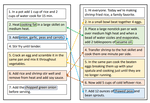
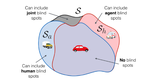
I led a team at DataRobot (2024-2025) and built Syftr which automatically optimizes for the Pareto-frontier of cost, latency and efficiency for agents.
I also love to build high-quality software for e.g.,
- Archai a PyTorch-based Neural Architecture Search framework. Models produced by Archai are used by millions worldwide every day and handle billions of queries.
- AirSIM a photo-realistic simulator for robotics which is widely used by the community.
- Syftr an automatic agentic workflow optimizer which searches for the Pareto-frontier of cost vs. latency vs. accuracy for agentic tasks.
I finished my PhD at the Robotics Institute, Carnegie Mellon University. My interests include decison-making under uncertainty, reinforcement learning, artificial intelligence and machine learning. My work has been honored with Best Paper of the Year Shortlist at the International Journal of Robotics Research. I give back to the AI community by regularly Area Chairing for ICML, NeurIPS, ICLR.
Interests
- Generative AI Efficiency
- Neural Architecture Search
- AutoML
- Reinforcement Learning
- Robotics
- Planning
- Vision
Education
-
PhD in Robotics, 2015
Carnegie Mellon University
-
MS in Robotics, 2012
Carnegie Mellon University
-
Bachelor of Electrical Engineering, 2007
Delhi College of Engineering